
1. 前言
数据架构最开始是filebeat直接入ES,但是由于后面扩充了filebeat节点数量,这就导致了2个问题,第一个是如果遇到解析方面的修改,那么需要修改多个filebeat,很麻烦;第二个是多个filebeat入库,时常导致ES集群崩溃。鉴于这两个原因,将架构切换为了filebeat入logstash,logstash再入ES。
logstash的配置如下:
CPU: 32核
JVM:31G
机器内存:96G
带宽:内网千兆
logstash.yml:
xxxxxxxxxx71http.host"0.0.0.0"2pipeline.workers323pipeline4 batch5 size30006 delay57pipeline.orderedfalse平均一条json数据是:90KB。
当架构切换为ELK时,又遇到了一个问题,查看kibana上面的监控显示:logstash到ES的吞吐量远远<=500/s,并且输入数据呈现波浪状,一会高达几百,一会儿变为0。
怀疑是kibana监控的问题,又用Prometheus搭建了一个监控,这个监控可以额外看到heap和GC。但是,该监控的显示的平均速度依然几百/s。当排除了是监控计数的问题后,又通过Events in 、Filtered rate 和 Events out 进行对比,发现filter和out的速度都跟得上in的速度。并且通过htop观察到CPU的占用率只有30%左右,nload只有9左右;通过iftop观察到网络带宽占用基本上没有。
根据监控的数据,推断瓶颈在于输入这端,但是不确定是filebeat造成的,还是logstash造成的,然后开始了试错过程。
2. 试错过程
1. 调整filebeat配置
调整了filebeat的queue.mem、bulk_max_size、worker,调整情况如下,这两个参数意思如下:
queue.mem.events:表示filebeat可以在内存中存储多少个事件,一条数据算一个事件,如果output消费不赢,并且达到了该值,就会阻塞harvest。将该值调大,可以避免读文件浪费的时间,默认是4096,设置为20000。queue.mem.flush.min_events:表示当满足了该值,就可以将事件发送到output。默认是2048,设置为4096。queue.mem.flush.timeout:表示min_events最多等待时间。默认是1s,设置为2s,如果超过2s,不管是否达到4096,都会发送事件到output。bulk_max_size:output一次性最多可以处理的事件,增大该值可以减少发事件的次数。默认2048,设置为4096。worker:output的给每个host设置的线程数量,默认是1。下面配置中,设置了3个host,两个worker,所以最终的线程数是:2*3=6。
xxxxxxxxxx251filebeat.inputs2typelog3 max_bytes1048576004 paths5/data/hcl/a.json6 close_eoftrue7
8logging.levelinfo9
10
11queue.mem12 events2000013 flush.min_events409614 flush.timeout2s15
16
17output.logstash18 hosts"172.16.80.x:8100" "172.16.80.x:8101" "172.16.80.x:8099"19 loadbalancetrue20 worker221 compression_level322 timeout80s23 bulk_max_size409624 ssl.certificate_authorities"/data/hcl/logstash.crt"25 ssl.verification_modenone
这次测试数据总量为4w条,本以为logstash显示Events in rate可以快速增长,但事与愿违,从监控上看到的事件输入和处理速度仍然<=500/s,处理4w条数据,耗时20分钟以上,这不经让我沉思。
首先排除掉是filebeat机器配置的问题,因为filebeat所在机器的CPU和内存占用都很低,并且网络占用,也仅仅只在最开始发送数据时有占用,其他时间基本为0。
再查看filebeat的日志,发现filebeat的第一批数据很快就发送出去了,harvset是在阻塞的状态,再结合网络占用基本为0,由此,确定是output的消费速度没有跟上,即logstash没有跟上filebeat推的速度。
首先排除网络传输原因,再根据之前观察的情况,确定问题出在logstash的input上
2. 排除compression_level
filebeat的压缩等级设置为3,采用的是gzip压缩。怀疑是不是logstash将事件消耗在解压数据上了,于是将其设置为0,发现只是稍微增加了传输耗时,数据依然恰在了logstash的input处,还没进入filter。
3. 是不是logstash的beats处理比较大的数据太慢?
为了验证这个问题,将logstash的input修改为从本机文件中读,配置如下,测试结果显示4w行的json文件,从读文件到输出完成,耗时不到40秒。
xxxxxxxxxx291input 2 file 3 path => "/data1/logstash/a.json"4 mode => "tail"5 start_position => "beginning"6 close_older => "5 sec"7
8 9 10 11
12filter 13 mutate14 remove_field => "@version""host""path""ecs""tags""fields""log""input""agent"15 16 json 17 source => "message"18 19 mutate20 remove_field => "message"21 22 23
24
25output 26 stdout27 28 29可以确定问题就出来logstash的beats插件,接下来就是找到出问题的到底是beats哪部分。
3. 调试logstash-input-beats
beats插件是由ruby和java编写的,java是核心处理代码,ruby是启动代码。首先看看ruby是如何启动beats服务的,在logstash-input-beats-6.1.2-java/lib/logstash/inputs/beats.rb,首先通过注册器注册了一个beats服务,然后在服务中注册了一个监听器,每次到来的数据都会放入MessageListener类处理。
xxxxxxxxxx221 def create_server2 server = org.logstash.beats.Server.new(@host, @port, @client_inactivity_timeout, @executor_threads)3 if @ssl4 ssl_context_builder = new_ssl_context_builder5 if client_authentification?6 if @ssl_verify_mode == "force_peer"7 ssl_context_builder.setVerifyMode(org.logstash.netty.SslContextBuilder::SslClientVerifyMode::FORCE_PEER)8 elsif @ssl_verify_mode == "peer"9 ssl_context_builder.setVerifyMode(org.logstash.netty.SslContextBuilder::SslClientVerifyMode::VERIFY_PEER)10 end11 ssl_context_builder.setCertificateAuthorities(@ssl_certificate_authorities)12 end13 server.setSslHandlerProvider(new_ssl_handshake_provider(ssl_context_builder))14 end15 server16 end17
18 def run(output_queue)19 message_listener = MessageListener.new(output_queue, self)20 @server.setMessageListener(message_listener)21 @server.listen22 end # def runMessageListener获取了每一条数据传入java处理,加上时间打印后,发现瓶颈不在此处。那么问题肯定出在了核心的java代码上。
xxxxxxxxxx251 def onNewMessage(ctx, message)2 puts "onNewMessage start:" + Time.new.inspect3 hash = message.getData4 ip_address = ip_address(ctx)5
6 unless ip_address.nil? || hash['@metadata'].nil?7 set_nested(hash, @input.field_hostip, ip_address)8 end9 target_field = extract_target_field(hash)10
11 extract_tls_peer(hash, ctx)12
13 if target_field.nil?14 event = LogStash::Event.new(hash)15 @nocodec_transformer.transform(event)16 @queue << event17 else18 puts "onNewMessage enter call:" + Time.new.inspect19 codec(ctx).accept(CodecCallbackListener.new(target_field,20 hash,21 message.getIdentityStream(),22 @codec_transformer,23 @queue))24 end25 end修改logstash启动的jvm参数,开启远程debug,对Message的getData方法下断点src/main/java/org/logstash/beats/Message.java,发现即使只传输5000条数据,也等了很久,才触发getData方法的断点。可知导致问题出现的地方还在更前面的位置,通过观察调用栈,有一个类引起了我的注意:BytetoMessageDecoder,该方法是对数据进行解码。
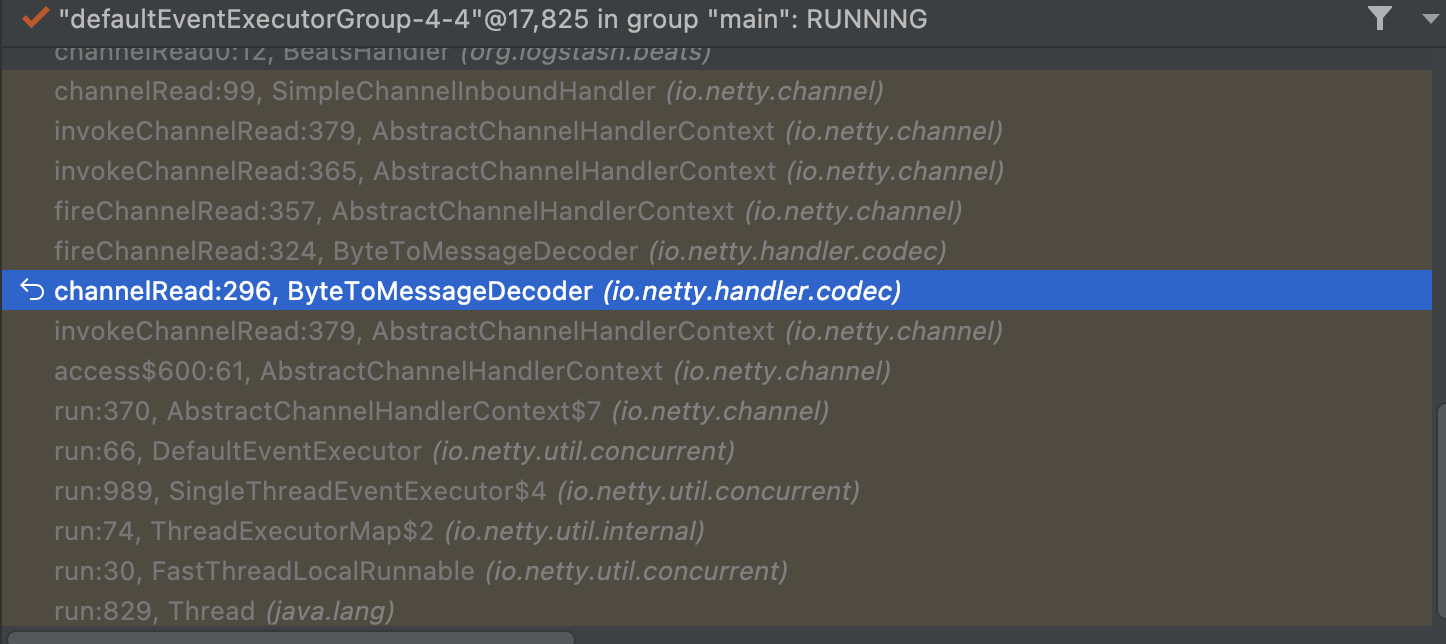
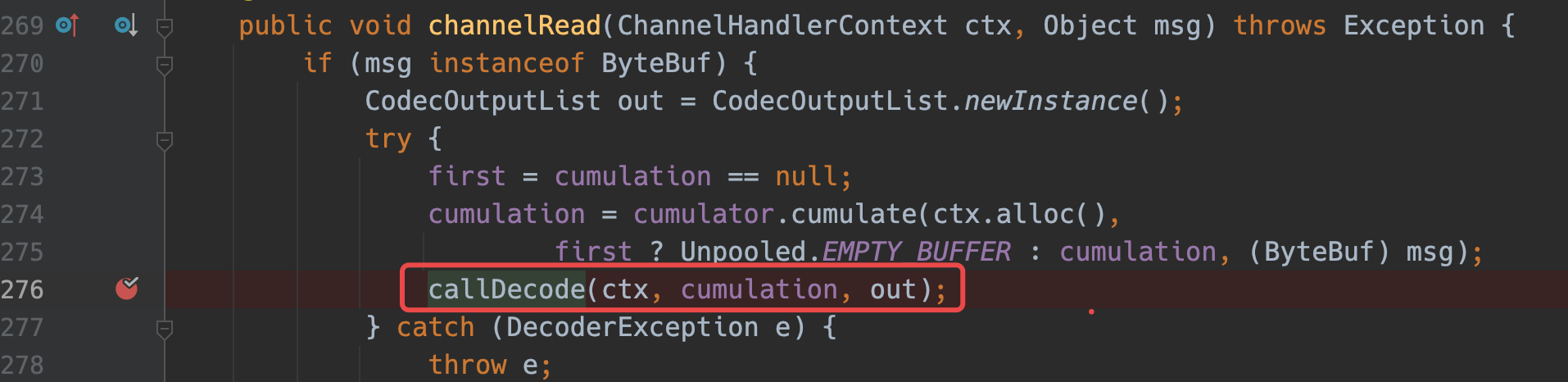
此处调用callDecode对数据解码,对该方法下断点,跟进decodeRemovalReentryProtection方法,最终会进入decode方法。在调试时就发现callDecode偶尔会有一点卡顿,而样本数据的某些行,一行数据甚至超过了10m,所以,大概率是decode问题。

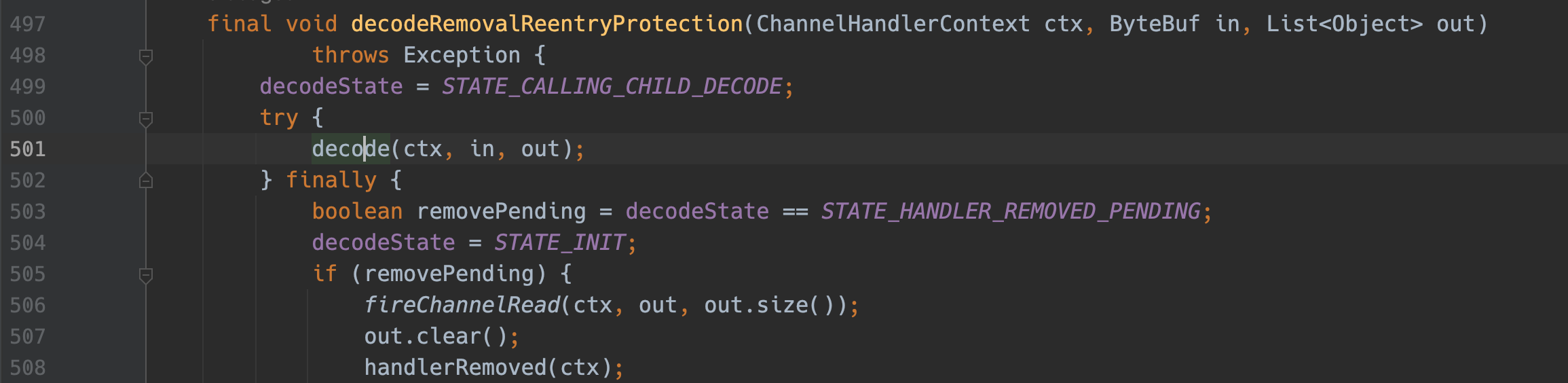
decode会进入处理json的逻辑,addMessage会当每一条消息到来就去扩容一次,而且每次扩容都只扩
这个设计,应该是为了避免浪费JVM内存,所以选择了一次性扩一点。
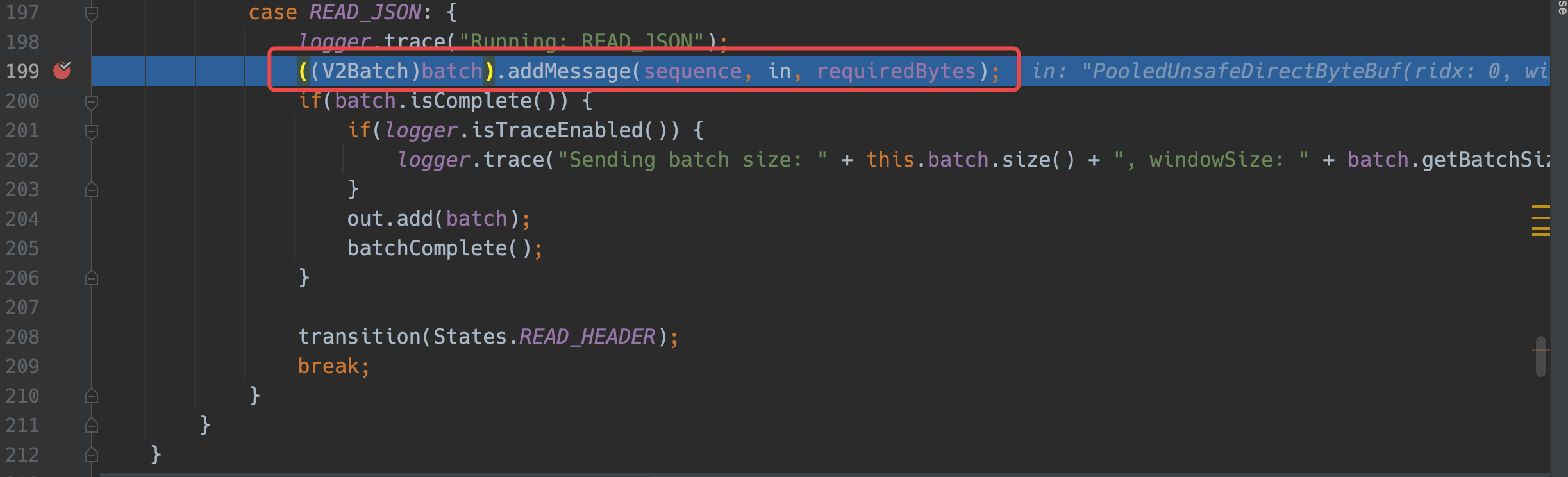

4. 解决方案
通过增加扩容的字节数,减少扩容次数。
最后,当修改完毕,想通过官方推荐的方案使用logstash-plugin install时,遇到了极大的坑,安装显示成功,但是由于没有编译,所以报错了。然后打算通过ruby的bundle install安装依赖,再使用gem build编译,遇到依赖冲突了。折腾了半天,发现ruby编译太麻烦了,突然想到直接替换jar不就好了嘛?然后在本地通过gradle vendor编译。
上线后,速度提升不止10倍。但长期观察后,发现如果ES的吞吐跟不上logstash的接收速度,那么会导致logstash内存崩溃。所以,调整时需根据自身情况调整扩容方式。
5. 后续遇到问题
针对第4部分的,当遇到filebeat推送速度超过了logstash的写入速度,此时瓶颈在es的写入速度上。由于logstash没有速度限制器,会导致出现以下2个问题。这两个问题都是由于Direct buffer溢出导致,根本原因则是没有限速器。
xxxxxxxxxx61io.netty.handler.codec.DecoderException: java.lang.IllegalArgumentException: newCapacity: -21474836482LEAK: ByteBuf.release() was4not called before it's garbage-collected. See https://netty.io/wiki/reference-counted-objects.html for more information.5...6logstash java.lang.OutOfMemoryError: Direct buffer memory
针对出现的两个问题,通过搜索logstash-input-beats的issue,可以找到有前人已经遇到过该类问题,并且已经提出了PR,但该PR还没被合并。
该PR是基于475和410的,通过检查PR475,发现该PR实现了两个功能,其原理可以参考netty4-数据读取性能大于处理时“直接内存水位处理器”使用:
将beats的push-read方式替换为pull-read,可以控制beats端的速度
当遇到快接近oom时,则丢弃新来的beats链接
由于475是410的增强版,所以我们只需要合并PR475即可。
5.1 修改logstash-input-beats
xxxxxxxxxx151# 1. clone 主分支2git clone https://github.com/logstash-plugins/logstash-input-beats.git3
4# 2. 拉取提交的PR 5git pull origin pull/475/head:mitigate_thundering_herd_26
7# 3. 合并PR8git merge mitigate_thundering_herd_29
10# 4. 存在冲突需要手动修改代码(由于我使用的主分支是6.8.0和作者andsel不是同一个主分支,需要需要修改代码)11
12# 5. 继续合并13git merge --continue14
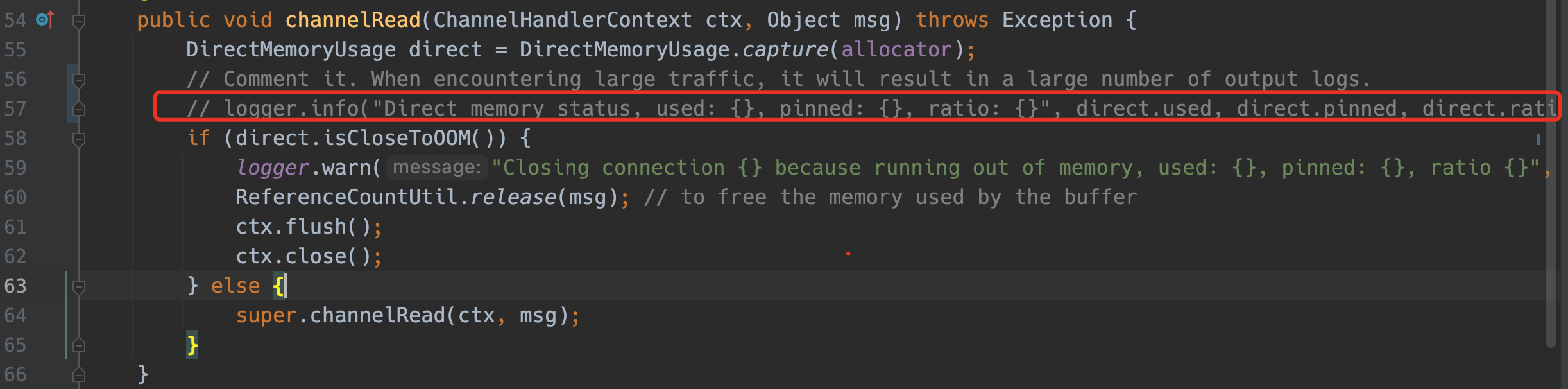
15# 6. git add&git commit提交到本地仓库合并完分支后,还需要注释以下代码src/main/java/org/logstash/beats/OOMConnectionCloser.java,避免过多的日志打印:
5.2 编译与安装
1. 如果是在插件本身的版本是6.8.0,则直接替换vendor
完成代码后,使用./gradlew vendor编译jar,会生成一个叫做vendor的目录,如果是在6.8.0版本的插件上使用,可以直接替换vendor目录。
2. 其他版本
在其他版本的插件修改,需要先通过以下命令编译成gem文件(注:由于logstash的版本不同,可能会遇到Ruby的依赖冲突问题,需自行解决依赖冲突问题,我使用的是logstash7.17.17,未遇到依赖冲突,8.0则有依赖冲突)。
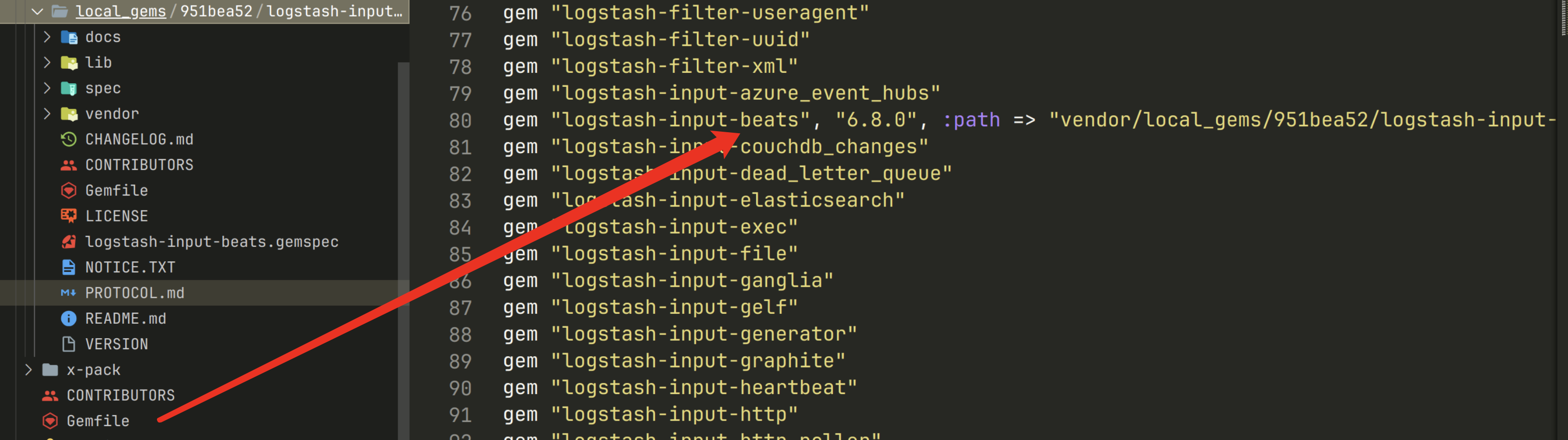
xxxxxxxxxx11gem build logstash-input-beats.gemspec然后在本地环境中,安装一次
xxxxxxxxxx11./bin/logstash-plugin install logstash-input-beats-6.8.0-java.gem安装beats完成后,可在logstash的gemfile中看到插件已被修改为自定义版本,位于localgems下。
接着,可以生成离线版的插件,供服务器使用或者打包整个logstash替换。
生成离线时,(注:由于ruby源在国外,需要在shell中挂上HTTP代理):
xxxxxxxxxx11bin/logstash-plugin prepare-offline-pack logstash-input-beats
安装:
xxxxxxxxxx11bin/logstash-plugin install file:///path/to/logstash-input-beats-6.8.0.zip
5.3 解决仍存在的bug
上线运行几天后,在直接batch.release()会遇到netty的内存释放引用计数错误,该问题可能导致batch未正确的释放,内存泄露。
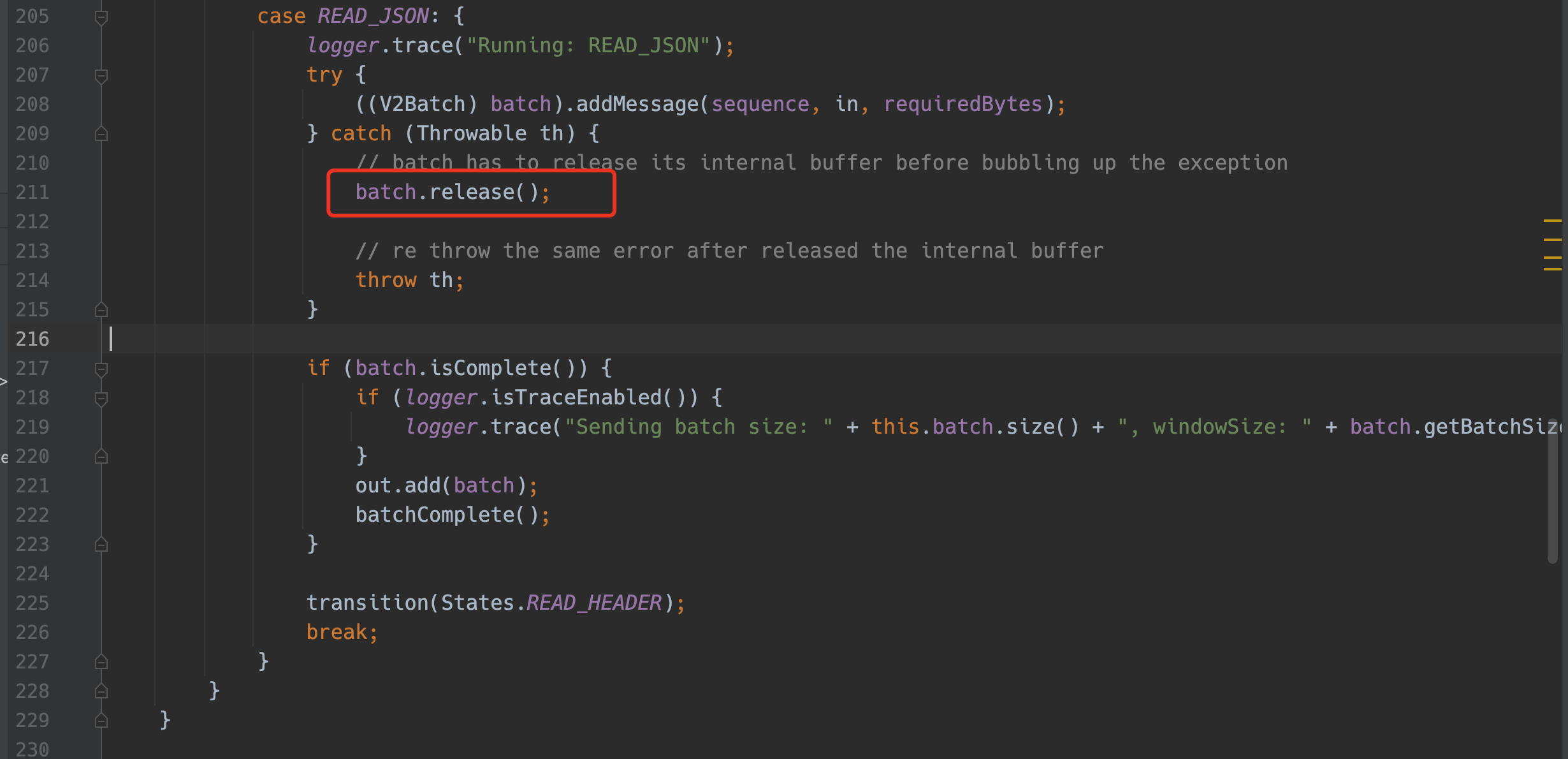
xxxxxxxxxx51Caused by: io.netty.util.IllegalReferenceCountException: refCnt: 0, decrement: 12at io.netty.util.internal.ReferenceCountUpdater.toLiveRealRefCnt(ReferenceCountUpdater.java:83) ~[netty-common-4.1.100.Final.jar:4.1.100.Final]3at io.netty.util.internal.ReferenceCountUpdater.release(ReferenceCountUpdater.java:148) ~[netty-common-4.1.100.Final.jar:4.1.100.Final]4at io.netty.buffer.AbstractReferenceCountedByteBuf.release(AbstractReferenceCountedByteBuf.java:101) ~[netty-buffer-4.1.100.Final.jar:4.1.100.Final]5at org.logstash.beats.V2Batch.release(V2Batch.java:105) ~[logstash-input-beats-6.8.0.jar:?]
发现该问题后,为了拿到更全面的日志输出,我将通过--log.level=debug添加到启动命令行,通过对日志进行分析后,发现最终引发问题的原因在于:
xxxxxxxxxx91Caused by: java.lang.IllegalArgumentException: newCapacity: -2147483648 (expected: 0-2147483647)2at io.netty.buffer.AbstractByteBuf.checkNewCapacity(AbstractByteBuf.java:1435) ~[netty-buffer-4.1.100.Final.jar:4.1.100.Final]3at io.netty.buffer.PooledByteBuf.capacity(PooledByteBuf.java:104) ~[netty-buffer-4.1.100.Final.jar:4.1.100.Final]4at org.logstash.beats.V2Batch.addMessage(V2Batch.java:93) ~[logstash-input-beats-6.8.0.jar:?]5at org.logstash.beats.BeatsParser.decode(BeatsParser.java:208) ~[logstash-input-beats-6.8.0.jar:?]6at io.netty.handler.codec.ByteToMessageDecoder.decodeRemovalReentryProtection(ByteToMessageDecoder.java:529) ~[netty-codec-4.17.100.Final.jar:4.1.100.Final]8at io.netty.handler.codec.ByteToMessageDecoder.callDecode(ByteToMessageDecoder.java:468) ~[netty-codec-4.1.100.Final.jar:4.1.1900.Final]
错误是通过AbstractByteBuf.checkNewCapacity函数抛出,结合源码得知是申请后的容量超过了最大容量限制,而maxCapacity()的定义是int类型,那么容量最大也就是2GB。
xxxxxxxxxx71protected final void checkNewCapacity(int newCapacity) {2 ensureAccessible();3 if (checkBounds && (newCapacity < 0 || newCapacity > maxCapacity())) {4 throw new IllegalArgumentException("newCapacity: " + newCapacity +5 " (expected: 0-" + maxCapacity() + ')');6 }7}上文中,为了修复扩容过于缓慢的问题,我们将netty.ByteBuf的扩容方式改为了将当前容量*2,这就会导致如果当前容量为1GB时,无法处理完beats发来的一次完整的batch,那么就需要再次扩容,接着就发生容量超过2147483647字节的错误。
xxxxxxxxxx11internalBuffer.capacity(internalBuffer.capacity() * 2)
所以解决方式有两种:
降低beats每次发送数据batchSize,可通过估算每条数据byteSize*batchSize低于1GB
我的filebeat设置的batchSize是4096条,为了避免更改多个filebeat端的配置,修改扩容方式如下:
xxxxxxxxxx191void addMessage(int sequenceNumber, ByteBuf buffer, int size) {2written++;3// if (internalBuffer.writableBytes() < size + (2 * SIZE_OF_INT)){4// internalBuffer.capacity(internalBuffer.capacity() + size + (2 * SIZE_OF_INT));5// }6while (internalBuffer.writableBytes() < size + (2 * SIZE_OF_INT)){7// Avoid memory overflow in extreme situations8if (internalBuffer.capacity() * 2 > 2147483647) {9internalBuffer.capacity(internalBuffer.capacity() + (13421772 * SIZE_OF_INT));10}11else internalBuffer.capacity(internalBuffer.capacity() * 2);12}13internalBuffer.writeInt(sequenceNumber);14internalBuffer.writeInt(size);15buffer.readBytes(internalBuffer, size);16if (sequenceNumber > highestSequence){17highestSequence = sequenceNumber;18}19}

Comments NOTHING